
Desde o início dos tempos, a humanidade tem sido fascinada pela ideia de prever o futuro. Do olhar para as estrelas até a interpretação dos sonhos, sempre buscamos maneiras de antecipar o que está por vir. A jornada humana para prever o futuro é uma trama tecida através de séculos, entrelaçando a imaginação literária com marcos científicos.
No universo literário, podemos citar aqui romances de ficção científica, como a série “Foundation” de Isaac Asimov, onde explora-se a “psico-história” [1], uma ciência que prevê o futuro da humanidade. O tema também foi especulado por autores como Arthur C. Clarke e Philip K. Dick, escrevendo sobre os limites da previsão e da realidade.
Já na ciência, essa busca pelo entendimento do futuro encontrou um pilar em Alan Turing, cujas ideias fundamentais sobre computação abriram caminho para o que sabemos hoje sobre processamento de dados. Turing não apenas sonhou com máquinas que poderiam pensar, mas também lançou as bases para que isso se tornasse realidade.
Essa busca por essa nova realidade não apenas moldou nossas histórias e culturas, como também impulsionou o desenvolvimento de uma das mais revolucionárias invenções da nossa era: a inteligência artificial (IA).
Em um mundo em constante mudança e com cada vez mais necessidade de processar dados, tornou-se inevitável organizá-los de modo estruturado e reaproveitável.
A evolução da organização de dados
Com o surgimento dos bancos de dados relacionais na década de 70 a organização estruturada dos dados tornou-se cada vez mais essencial, estabelecendo a base fundamental dos diversos sistemas de informação existentes até os dias atuais.
Nesta mesma época, as principais teorias sobre inteligência artificial estavam sendo elaboradas. Teorias estas que somente nas últimas décadas puderam ser aplicadas em grande escala, principalmente pelo advento de novas tecnologias de processadores e também pela quantidade significativa de dados que atualmente estamos gerando.
O papel dos bancos de dados relacionais
Neste cenário, onde a inteligência artificial espera cada vez mais volumes massivos de dados, bem como formas de armazenamento e processamento cada vez mais sofisticadas, os bancos de dados relacionais enfrentam novos desafios. Algumas questões surgem neste momento:
- Sendo os bancos de dados relacionais os principais centralizadores das informações que norteiam os processos das organizações, quais recursos eles possuem para apoiar a análise de dados com foco em inteligência artificial?
- Se já temos uma tecnologia de gerenciamento de bancos de dados madura no ecossistema de nossa organização, até que ponto precisaremos aprender outras tecnologias de gerenciamento de bancos de dados?
Ao longo de uma séries de posts, iniciando com este, embarcaremos em uma jornada pelo desenvolvimento da inteligência artificial e como o PostgreSQL se destaca com sua robustez e extensibilidade, não só por ser um sistema de gerenciamento de dados tradicional, mas uma plataforma para desenvolvimento de soluções.
Explorando o potencial da Inteligência Artificial com PostgreSQL
O Postgres, conhecido por sua robustez e confiabilidade, também se destaca pela sua adaptabilidade. Ele tem evoluído para lidar não só com o volume de dados massivos, mas também com a complexidade crescente desses dados. Tendo como um dos seus principais triunfos a extensibilidade, esta característica permite ao Postgres customização de suas funcionalidades atuais e a expansão de novos recursos para atender às necessidades específicas de diferentes soluções.
O constante avanço das inteligências artificiais generativas e novas formas de aprendizado de máquina (Machine Learning ou ML) está redefinindo o que os gerenciadores de bancos de dados devem oferecer de recursos. Nesse cenário, o Postgres se adapta para suportar não apenas os tipos tradicionais de dados, mas também estruturas mais complexas, como as que são necessárias para os Vector Databases.
Um banco de dados vetorial se especializa em armazenar, pesquisar e manipular vetores de maneira rápida e eficaz, o que o torna ideal para tarefas que exigem análises avançadas e cálculos de similaridade em grandes conjuntos de dados. Os vetores são sequências de números ou representações de dados em um espaço multidimensional e são comumente utilizados em aplicações de aprendizado de máquina e inteligência artificial para representar e comparar características complexas de determinados dados em reconhecimento de imagem ou no processamento de linguagem natural.
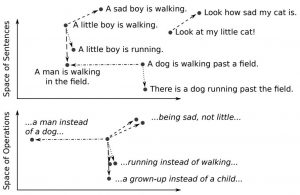 Figura 1: Uma ilustração de um espaço vetorial multidimensional contínuo representando frases individuais. Fonte: [2]
Figura 1: Uma ilustração de um espaço vetorial multidimensional contínuo representando frases individuais. Fonte: [2]
Então o Postgres pode ser um banco de dados vetorial também? Tudo indica que sim.
Tal como o Postgres se adaptou às novas tecnologias de estruturas de dados mais dinâmicas, como o JSON, e criou mecanismos para suportar a rápida recuperação de dados neste formato, seja por um armazenamento efetivo como o jsonb, seja pelo recurso de índices avançados como GIN,seu mecanismo de extensibilidade atual permitiu a existência de extensões como a pgvector [3], que surge como um esforço da comunidade Postgres de disponibilizar uma ferramenta que permite armazenar vetores junto com outros tipos de dados em um banco de dados PostgreSQL.
Ampliando as capacidades do Postgres com pgvector
O pgvector é uma extensão open source que concede ao Postgres o suporte ao tipo de dados vetor (vector), permitindo buscas exatas ou aproximadas, utilizando métricas como distância L2, produto interno e distância cosseno. Compatível com qualquer linguagem que possua um cliente Postgres, essa extensão também oferece as vantagens tradicionais do PostgreSQL, incluindo conformidade ACID (Atomicidade, Consistência, Isolamento, Durabilidade), recuperação de pontos específicos no tempo, possibilidade de realizar JOINs e todas as outras funcionalidades avançadas existentes no PostgreSQL.
Extensões como a pgvector e recursos nativos como JSON provam que o PostgreSQL está cada vez mais no centro de uma revolução de dados e de inteligência artificial. Sua evolução consistente e sua capacidade de adaptar-se a um mundo de dados cada vez mais complexo e faminto o tornam um componente indispensável para qualquer empresa que deseja explorar o potencial do aprendizado de máquina. À medida que avançamos, o Postgres não é apenas um SGDB; é um facilitador crucial no caminho para um futuro mais inteligente, sustentável e orientado a dados.
Quer saber mais sobre PostgreSQL, Machine Learning e pgvector? Continue nos acompanhando nesta série que trará conteúdos cheios de insights e conhecimentos práticos sobre o assunto.
Referências
[1] Wikipedia (2024). Psychohistory (fictional science). Link: https://en.wikipedia.org/wiki/Psychohistory_(fictional_science). Acessado em 09/04/2024.
[2] Petra Barančíková, & Ondřej Bojar. (2019). In Search for Linear Relations in Sentence Embedding Spaces. Link: https://arxiv.org/pdf/1910.03375v1.pdf#page=2. Acessado em 08/04/2024.
[3] Andrew Kane (2021). pgvector. Link: https://github.com/pgvector/pgvector. Acessado em 23/03/2024.