
Na PGConf.Brasil de 2022, Dickson Guedes, consultor da Timbira, realizou uma palestra sobre automação com SQL. Inicialmente, Guedes menciona que o título da palestra, assim como neste artigo, deveria estar incluso um ponto de interrogação: “Ganhe tempo automatizando com SQL?”. Isso porque, apesar da proposta desta palestra ser sair do psql para algo mais avançado, essa é apenas a ponta do iceberg. A automação com SQL envolve explorar paradigmas de programação e estratégias avançadas que transcedem o uso simples do psql como interface inicial. Esse é o objetivo da Palestra e agora, também, deste artigo.
Como é possível automatizar com SQL?
Existem diversos paradigmas de linguagem de programação. Por exemplo, na linguagem procedural, o foco está em como realizar as tarefas, enfatizando a sequência de ações necessárias para alcançar um resultado. No paradigma funcional, a ênfase recai sobre a imutabilidade, onde toda comunicação e execução de ações são realizadas por meio de mensagens. Independentemente do paradigma utilizado, uma linguagem de programação permite a construção, extensão e reutilização de códigos. Um exemplo básico é a atribuição de um valor a uma variável, como em variável =‘valor’.
Já o SQL é uma linguagem declarativa, onde você especifica o que deseja, sem definir como isso deve ser feito. Como uma linguagem declarativa, SQL não oferece a possibilidade de criar estruturas ou estender funcionalidades da mesma forma que outras linguagens. Por isso, não é possível, por exemplo, atribuir um valor a uma variável diretamente no SQL, como em variável =‘valor’. Para contornar essa limitação, podemos utilizar o psql, uma ferramenta que compreende melhor o SQL e opera em uma camada anterior ao próprio SQL. Assim, interagimos com o psql antes de enviar comandos SQL diretamente ao banco de dados.
Então talvez a palestra poderia se chamar “Ganhe tempo automatizando com psql”? O título pode parecer provocativo, mas o conteúdo é o que importa. No decorrer do texto você irá entender melhor as possibilidades da automação no psql. E, para isso, Guedes propõe que sigamos por níveis de complexidade porque, dessa forma, todos conseguem estar na mesma linha.
Nível 1. Variáveis e macros
O psql é um aplicativo de linha de comando que permite a conexão com uma base PostgreSQL para a realização de consultas interativas e visualização dos resultados. Além disso, oferece uma variedade de meta-comandos que possibilitam a execução de funções específicas no ambiente do PostgreSQL, como exibição de informações sobre tabelas, bancos de dados, usuários e configurações. Esses comandos iniciam com uma barra invertida e podem ser utilizados para configurar variáveis, como definir o nome da variável psql para um determinado valor ou para a concatenação de vários valores.
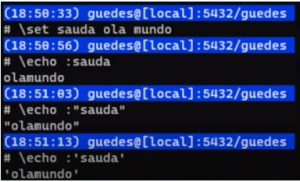
Ao utilizar esses comandos dentro do psql, utilizando a ‘\’ no início, o psql interpreta esse comando como um comando interno e faz algo antes. No exemplo abaixo, o psql atribui a variável ‘sauda’ o valor ‘ola mundo’.
Variáveis no psql
\set sauda ola mundo
\echo :sauda
\echo :“sauda”
\echo :‘sauda’
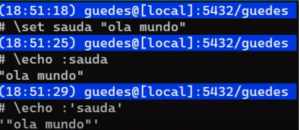
\set sauda “ola mundo”
\set sauda ‘ola mundo’
Como irá se comportar na prática? Veja nos exemplos abaixo:
Mas, e se, fizermos dessa forma?
\set sauda select ‘ola mundo!’;
:sauda
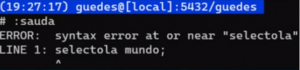
Deu erro! Será que não vai dar pra fazer? Será que dá pra fazer macro no psql? Dá sim!
\set top101 select * from pg_stat_activity order by 17, 13 desc limit 10;
\set top102 “select * from pg_stat_activity order by 17, 13 desc limit 10;”
\set top103 'select * from pg_stat_activity order by 17, 13 desc limit 10;'
Qual destes 3 comandos você acha que deve funcionar?
Ao executar o primeiro e segundo, eis o que ocorre:
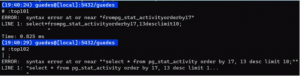
O erro está nas aspas duplas.
Ao executar o terceiro, ele dá a seguinte saída:
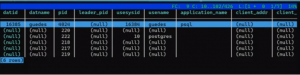
Esse primeiro momento é importante para fundamentar e facilitar o entendimento de como podemos utilizar isto para construir algo que pode ajudar a agilizar alguns tipos de procedimentos que costumamos executar dentro do psql.
Nível 2. Criando “comandos”
E se seguirmos utilizando esse mesmo conceito e condicionar a criação de variáveis com prefixos diferentes, o que ocorre? Veja os exemplos:
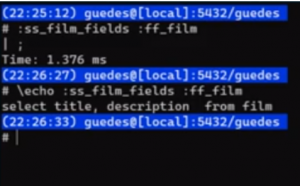
\set ss_film 'select * from film'
\set ss_film_fields 'select title, description'
\set ff_film ' from film'
\set jj_film_actor ' join film_actor using (film_id)'
\set jj_actor ' join actor using (actor_id)'
Concatenando, temos outras possibilidades:
:ss_film
:ss_film_fields :ff_film
:ss_film_fields, first_name :ff_film :jj_film_actor :jj_actor
Ao tentar executar tais comandos, temos a seguinte saída:
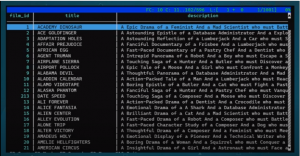
O que entendemos disso é que o psql expande. A partir disso, você consegue construir qualquer composição. Pode parecer apenas uma concatenação, mas estamos usando recursos do psql para tentar nos ajudar a não ter que escrever o comando inteiro todas as vezes, repetidamente. O objetivo é encontrar maneiras de automatizar e fazer a ferramenta trabalhar para você.
Nível 3. Vamos agora desconstruir!
select *
from pg_stat_all_tables
where age(now(),
coalesce(
last_autoanalyze,
last_analyze,
now() - interval ' 1 year '
)
) > interval ' 10 days '
and relname !~ ' ^ pg_toast_ | sql_ '
Esta é uma consulta para verificar tabelas que não tiveram ‘analyze’ e nem ‘autoanalyze’ em um intervalo de tempo de 10 dias. Por exemplo, se isto está em um ponto SQL, você pode ir no psql, digitar um ‘\i‘, passar o caminho e executar. Mas a ideia aqui é fazer isto de uma outra forma.
O que seria essa desconstrução? A partir da refatoração de códigos, olhar quais são as partes móveis do meu código, partes que eu posso reutilizar em outros locais e extrair isso para algum lugar.
select *
from pg_stat_all_tables
where age(now(),
:_analyze_mais_recente
) > interval '10 days'
and relname !~ '^pg_toast_|sql_'
\set _analyze_mais_recente 'coalesce(last_autoanalyze, last_analyze, now() - interval ''1 year'')'
select *
from pg_stat_all_tables
where age(now(),
coalesce(last_autoanalyze,
last_analyze,
now() - interval ' 1 year ')
) > interval ' 10 days '
and relname !~ ' ^ pg_toast_ | sql_ '
A diferença entre os dois é que o segundo tem a quebra de linha. Portanto, entendemos que não pode haver a quebra de linha.
select *
from pg_stat_all_tables
where age(now(),
:_analyze_mais_recente
) > interval ' 10 days '
and relname !~ ' ^ pg_toast_ | sql_ '
select *
from pg_stat_all_tables
where age(now(),
:_analyze_mais_recente) > interval '10 days'
and :_ignored_tables
\set _ignored_tables 'relname !~ ''^pg_toast_|sql_'''
Essa parte acima pode ser usada em várias outras consultas. Chamaremos de “tabelas ignoradas” e vamos criar uma variável para isso.
Podemos simplificar dessa forma:
select *
from pg_stat_all_tables
where age(now(),
:_analyze_mais_recente) > interval '10 days'
and :_ignored_tables
ss_mant_tabelas_analisadas_ha_mais_de_10_dias
Ao realizar essa simplificação, quando digitar ‘:ss’ e um ‘_mant’ dentro do psql, ele irá te mostrar todas as opções que começam com esse prefixo. Também podemos fazer isto utilizando essa variável:
with dados as (
:ss_mant_tabelas_analisadas_ha_mais_de_10_dias
)
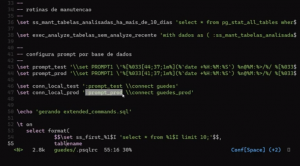
select format('ANALYZE %I', relname) from dados \gexec
Lembrando que não tem ponto e vírgula para justamente podermos injetar e reutilizar códigos dentro do psql. Gera-se uma saída com um comando ‘analyse’ onde passa o nome da ‘tabela from dados’. O que são dados? Dados são tabelas analisadas há mais de 10 dias. Então, ao ler essa consulta no próprio psql, conseguimos entender o que está acontecendo, no lugar de, por exemplo, ter que ler toda a consulta para interpretar o que está ocorrendo.
Vejamos como se comporta:

É por conta do ‘\gexec’. que a saída deste comando irá ser executada pelo psql.

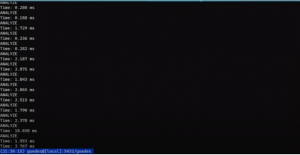
Ao rodarmos novamente:
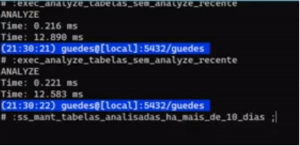
Ao inserir o select dentro do \exec., podemos executar uma macro que automatiza a ação desejada e, além disso, verificar tanto o conteúdo quanto a saída dessa execução.
Para tornar essa abordagem mais organizada, utilizamos um padrão de nomenclatura: para queries que executam uma ação, iniciamos o nome da variável com o prefixo exec_, e para queries que apenas consultam dados, utilizamos o prefixo ss_. No exemplo apresentado, a query que “apenas consulta os dados” (ss_) é utilizada dentro da “query que executa” (exec_). Dessa forma, a query verifica as tabelas que estão há mais de 10 dias sem executar o ANALYZE, e, por conta do
\gexec, já executa o ANALYZE nas tabelas identificadas. Ao executarmos essa consulta mais de uma vez, a primeira execução realmente realiza o ANALYZE, e, nas execuções subsequentes, a única linha retornada será a mensagem ANALYZE, indicando que as tabelas já foram analisadas. Esses padrões podem ser criados da forma que melhor funcionar para você.
Guedes finaliza esse nível opinando que:
\gexec e format( ) – a combinação perfeita
Nível 4. Format e \gexec
E se gerássemos um arquivo contendo todos esses comandos? Podemos criar um conjunto e definir um comando para sempre fazer um select em uma tabela, mostrando os 10 primeiros registros, por exemplo. Assim, fazemos um ‘select first’, passamos o nome da tabela e, sempre que digitarmos ‘:ss_first_nome_tabela’, ele executa um ‘select * from nome_tabela limit 10;’. Queremos aplicar isso a todas as tabelas, passando apenas o nome da tabela.
O símbolo $ funciona como aspas simples no Postgres. Usamos $$ para enclausurar o texto e evitar “poluição” no código. Dessa forma, podemos ver a sintaxe mais claramente em um editor de texto que apresenta o código com cores, facilitando a leitura.
Selecionamos a lista de tabelas, excluindo as tabelas do catálogo, e para cada tabela da lista, geramos um texto que é uma macro que começa com ‘ss first_’. Inserimos isso e geramos o SQL correspondente. Toda a exportação está no comando, e o ‘\g’ executa o comando, direcionando a saída para um arquivo.
select format(
$$\set ss_first_%1$I 'select * from %1$I limit 10;'$$,
tablename
)
from pg_tables
where schemaname !~ '(pg_catalog)'
\g /home/guedes/extended_comands.sql
Uma forma de chamar o mesmo valor mais de uma vez sem precisar repetir é usando o símbolo ‘%1$I’ no format para referir-se ao argumento tablename. Dessa forma, não é necessário repetir o comando cada vez que ele for chamado. É um atalho, similar ao nosso %I, mas adiciona o 1$ para indicar que é o primeiro argumento.
# .psqlrc
… corte …
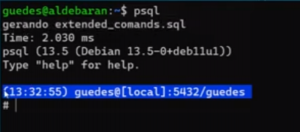
\echo 'gerando extended_commands.sql'
\t on
select format(
$$\set ss_first_%1$I 'select * from %1$I limit 10;'$$,
tablename
)
from pg_tables
where schemaname !~ '(pg_catalog)'
\g /home/guedes/extended_commands.sql
\t off
\ir extended_commands.sql
A saída disso está em um arquivo chamado ‘.psqlrc’, localizado no diretório home do usuário. Ao ser lido pelo psql durante a inicialização, este arquivo executa todos os comandos nele contidos (inclusive se tiver um ‘drop database’ que seu colega pode ter deixado ali para te trollar no primeiro dia de trabalho).
A ideia aqui é simples: mover essas configurações para o arquivo ‘.psqlrc’ para que sejam automaticamente executadas quando o psql é aberto. Por exemplo, podemos usar o comando ‘\echo’ para imprimir mensagens e ‘\t on’ para mostrar apenas os dados, sem os nomes das colunas e a contagem de registros. O comando ‘\t off’ desativa essa opção. Como o ‘.psqlrc’ está localizado no diretório home, o comando ‘\i’ do psql pode importar seu conteúdo e executar os comandos nele presentes. Para facilitar a modularização, o comando ‘\ir’ permite trabalhar com caminhos relativos ao arquivo que está sendo executado. Isso é especialmente útil quando você deseja organizar seu trabalho em módulos, carregando um conjunto de arquivos de forma eficiente e mantendo a estrutura de diretórios limpa e organizada.
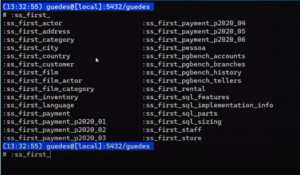
Dessa forma, é criado um ‘ss_first_’ para cada tabela existente dentro do banco.
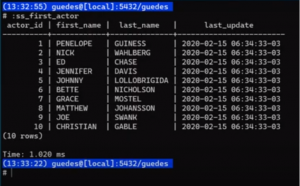
Foi criado um atalho no psql, como se fosse uma macro. Com a prática, você cria um mecanismo de macros dentro do seu psql.
O que mais dá para fazer?
No exemplo abaixo, o psql está gerando dois arquivos: 1 arquivo estendido e 1 arquivo de ’joins’:
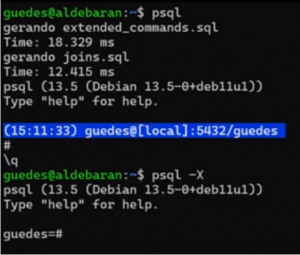
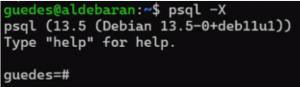
Se quiser garantir que o ‘script bash’ não leia o ‘.psqlrc’, use o parâmetro ‘-X’.
Ao utilizar ‘:ss’, você irá mostrar tudo que começa dessa forma. No exemplo abaixo, são apresentadas algumas convenções:
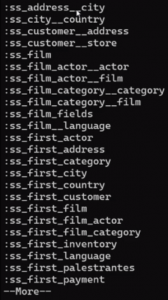
Por exemplo, se digitarmos o ‘:ss_film’ e pressionarmos a tecla ‘Tab’ serão mostradas todas as opções de macro relacionadas:

Quando você utiliza o comando ‘\echo’ antes de ‘:ss_film_actor__actor’, a forma expandida da macro será exibida. Isso significa que um comando ‘SELECT’ completo é gerado no momento em que você entra no psql. Essa funcionalidade existe porque o ‘.psqlrc’ já contém a configuração necessária para criar essa macro.

A partir disso, temos algumas possibilidades. Podemos fazer join com _actor ou com _film, e como resultado, teremos a seguinte saída:
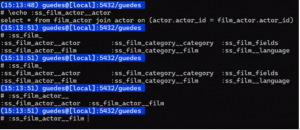
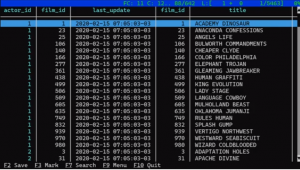
Uma observação: Guedes utiliza um utilitário chamado ‘pspg’, que permite uma saída em formato de tabela no psql . É importante destacar que o pspg não vem instalado automaticamente com o psql; é necessário instalá-lo separadamente em sua máquina ou servidor.
No preâmbulo abaixo, vemos alguns itens do psql, como o
PAGER ‘pspg’ e um histórico separado para cada banco de dados. O psql oferece o ‘:DBNAME’, que identifica o banco de dados em que estamos logados, permitindo realizar ações interessantes e úteis. No PROMPT, utilizamos caracteres de escape para adicionar cores. Abaixo, apresentamos os testes realizados.
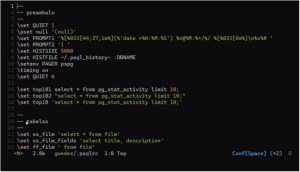
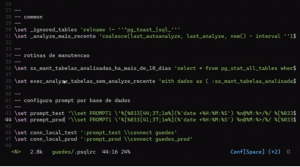
Definir o prompt no psql permite uma interação mais dinâmica com a ferramenta. Por exemplo, é possível inserir o nome do banco de dados em que você está logado. Esse conjunto de pseudomacros pode ser utilizado para gerar scripts ou tornar scripts existentes mais concisos, reduzindo códigos repetitivos com macros reutilizáveis. Assim, você pode criar pequenos atalhos para automatizar algumas tarefas, ganhando eficiência no uso do psql.
Seguindo essa linha de raciocínio sobre como integrar e compor funcionalidades no psql, você pode definir variáveis como ‘\set prompt_test’ e ‘\set prompt_prod’ para configurar o prompt de acordo com o ambiente. O comando ‘\set’ permite configurar variáveis que podem ser usadas para facilitar a execução de comandos. Por exemplo, ao usar a variável ‘prompt_test’ antes de um comando do psql, você pode se conectar a uma base de dados específica, já que o psql permite a execução de vários comandos em uma única linha.
No caso do ‘prompt_test’, ele configura o prompt para indicar que você está no ambiente de teste, tornando a administração do banco de dados mais clara e organizada.
Considerações finais
Você pode expandir as funcionalidades do seu psql utilizando esses recursos, e há muitas possibilidades a partir disso. Apesar de ser uma funcionalidade simples, muitas pessoas não conhecem esse mecanismo do psql. O objetivo é adicionar mais ferramentas ao seu repertório, revisando seus scripts atuais e questionando se é possível melhorar os códigos.
Reduzir a digitação com pseudo comandos como ‘:ss_’ e explorar outras opções pode não ser algo que atraia você, mas pode ser extremamente útil para iniciantes que estão dando os primeiros passos no uso do psql no dia a dia de trabalho. Esses recursos facilitam a automação e a eficiência, tornando o psql uma ferramenta ainda mais poderosa.